Data Lineage: Understanding Data Flow
Data lineage is one of the most powerful features in Ilum, providing comprehensive visibility into the flow of data across your organization. This guide explores how data lineage works, its benefits, and practical use cases for implementing data lineage in modern data platforms.
Understanding Data Lineage
What is Data Lineage?
Data lineage is the process of tracking and documenting the flow of data from its origin to its destination. It captures metadata about data sources, transformation rules, and dependencies to provide a comprehensive view of the data lifecycle. Data lineage helps organizations understand data by documenting how data moves through various data systems and data pipelines.
The lineage process tracks:
- Data origins and data sources
- Data transformation operations applied
- Intermediate data processing steps
- Final data destinations
- Dependencies between data elements
Lineage services track only metadata - they do not store or provide access to the actual data itself.
How Data Lineage Works
Data lineage works by capturing metadata at each stage of the data pipeline. The data lineage tool identifies data sources and their schemas, records data transformation and data mapping rules, documents data changes, and builds relationships between datasets and jobs.
In Apache Spark environments, data lineage uses an External Spark Listener Class that observes key events:
- Job creation and execution
- Dataset reads and writes
- Data transformation operations
When these events occur, the listener sends corresponding metadata to a lineage service (such as Marquez) using standardized formats like OpenLineage. This automated data lineage approach enables data engineers to capture lineage without manual intervention.
Why Data Lineage is Important
Data lineage is important for modern enterprise data management. The benefits of data lineage include:
- Regulatory Compliance: Maintains audit trails for GDPR, CCPA, and other regulatory frameworks, especially for sensitive data
- Transparency: Documents data origins, transformations, and destinations
- Troubleshooting: Enables rapid tracing of data quality issues to their source
- Data Governance: Aligns data practices with governance policies and ensures data integrity
- Impact Analysis: Assesses downstream effects of schema or data pipeline changes
Data lineage provides visibility into data movement and enables organizations to manage data effectively across complex data systems.
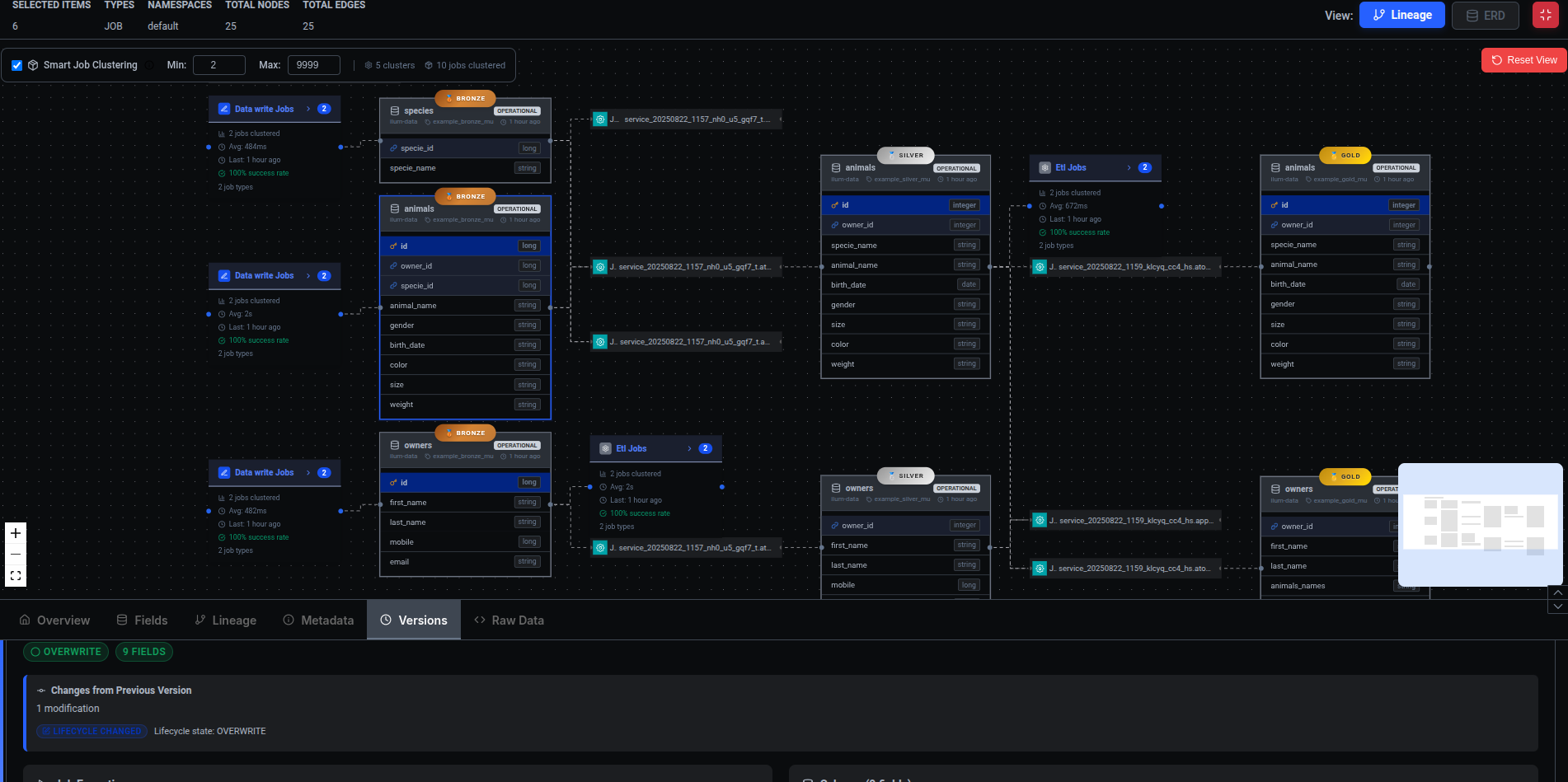
Ilum Data Lineage Implementation
Ilum integrates Marquez as its lineage service. When enabled, Ilum automatically configures jobs to use the OpenLineage listener and provides a UI to visualize data flows.
Ilum's Marquez Fork: Upstream-First Approach
As early Marquez adopters, Ilum runs Marquez in production for comprehensive lineage and metadata tracking. To maintain continuous development while ensuring stability, Ilum maintains a fork of Marquez with the following principles:
- Drop-in compatibility: 100% compatible with upstream Marquez API and data model
- Non-breaking improvements: Stability fixes and additive features (including a Search API)
- Upstream-first strategy: All battle-tested enhancements are contributed back to the Marquez project
- Zero breakage policy: No breaking changes to existing APIs or storage schemas
The fork exists to enable rapid iteration while maintaining full compatibility with the OpenLineage specification and upstream Marquez. Starting with Marquez 0.52.x, Ilum is upstreaming features incrementally, focusing on safety and backwards compatibility. Ilum does not use marquez-web; instead, it provides a custom UI optimized for large-scale lineage exploration, searchability, and operational tooling.
This approach ensures that data lineage solutions remain stable and reliable while contributing improvements back to the open-source community.
By default, Marquez is not enabled. To enable it, refer to the Production page.
Access the lineage page via the Lineage tab in the sidebar.
Spark OpenLineage Integration
Ilum configures every job with the following parameters to capture lineage automatically:
spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener
spark.openlineage.transport.type=http
spark.openlineage.transport.url=<MARQUEZ_URL>
spark.openlineage.transport.endpoint=/api/v1/lineage
This configuration applies to all job types, including SQL execution engines, ensuring comprehensive lineage across all data systems.
Only jobs launched after enabling lineage tracking will be captured.
Visualizing Data Flow with Lineage Diagrams
Ilum provides data lineage tools in two main areas:
- Dedicated Lineage Page: Per-job lineage views
- Table Explorer Integration: Table-specific lineage within the data explorer
Graph Components
Data lineage diagrams consist of:
- Job nodes: Represent jobs that produce or consume data assets
- Dataset nodes: Represent data assets produced or consumed by jobs
- Edges: Illustrate relationships and data flow between jobs and datasets
These data lineage diagrams visually represent the flow and transformation of data through your pipelines.
Column-Level Lineage
Ilum tracks column-level lineage through the OpenLineage specification, providing granular visibility into how individual columns are derived, transformed, and consumed across your data pipelines.
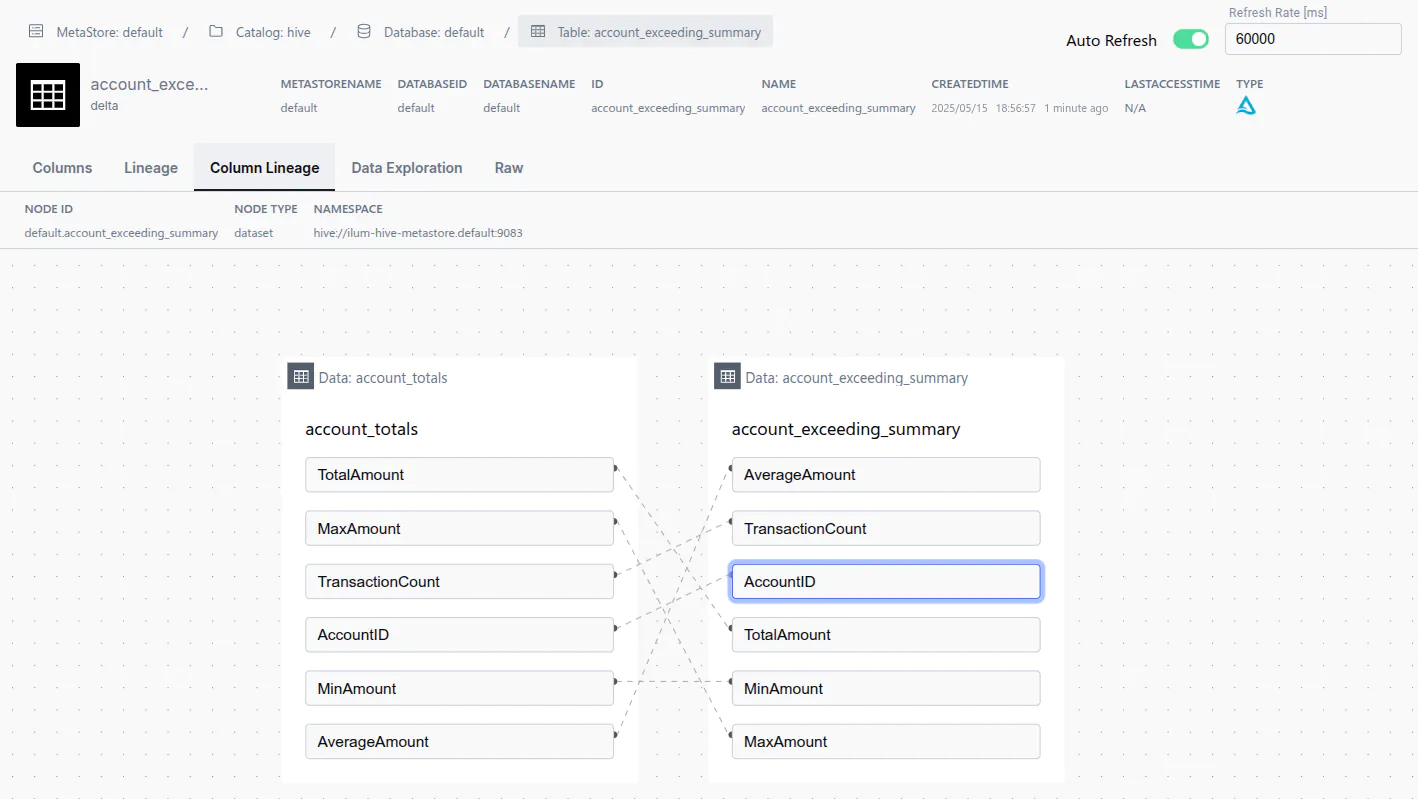
Supported Transformations
The OpenLineage Spark listener automatically captures column-level lineage for the following transformation types:
| Transformation | Column Lineage Captured | Notes |
|---|---|---|
SELECT / Projections | Yes | Direct column mappings |
JOIN operations | Yes | Tracks join key relationships |
GROUP BY / Aggregations | Yes | Maps input columns to aggregated outputs |
CASE / Conditional expressions | Yes | Tracks all branch inputs |
UDFs (User-Defined Functions) | Partial | Requires UDF annotation for full tracking |
| Complex nested transformations | Partial | Depth depends on OpenLineage version |
Configuration
Column-level lineage is enabled by default when Marquez lineage is active. To ensure maximum lineage depth, verify these OpenLineage settings:
spark.openlineage.transport.type=http
spark.openlineage.transport.url=<MARQUEZ_URL>
spark.openlineage.transport.endpoint=/api/v1/lineage
# Enable column-level lineage (default: true in recent versions)
spark.openlineage.facets.columnLineage.enabled=true
Known Limitations
- UDFs without annotations: Custom UDFs that don't implement OpenLineage's
ColumnLineageVisitorinterface appear as opaque transformations. Input columns are tracked but the specific mapping to output columns may not be captured. - Dynamic SQL: Queries constructed dynamically at runtime (e.g., via string interpolation) may have incomplete column lineage if the SQL text is not visible to the listener at plan time.
For the most complete column-level lineage, use the latest OpenLineage Spark listener version and prefer declarative SQL transformations over imperative DataFrame operations.
Next-Generation Lineage Features
Ilum's lineage solution includes advanced capabilities for understanding data flow across bronze → silver → gold layers.
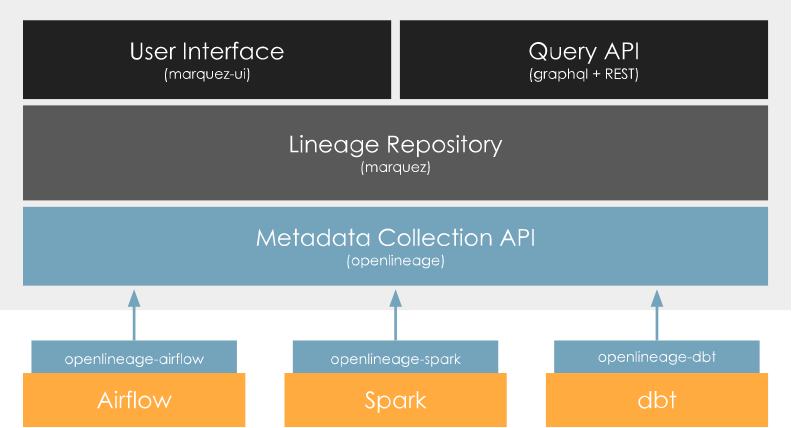
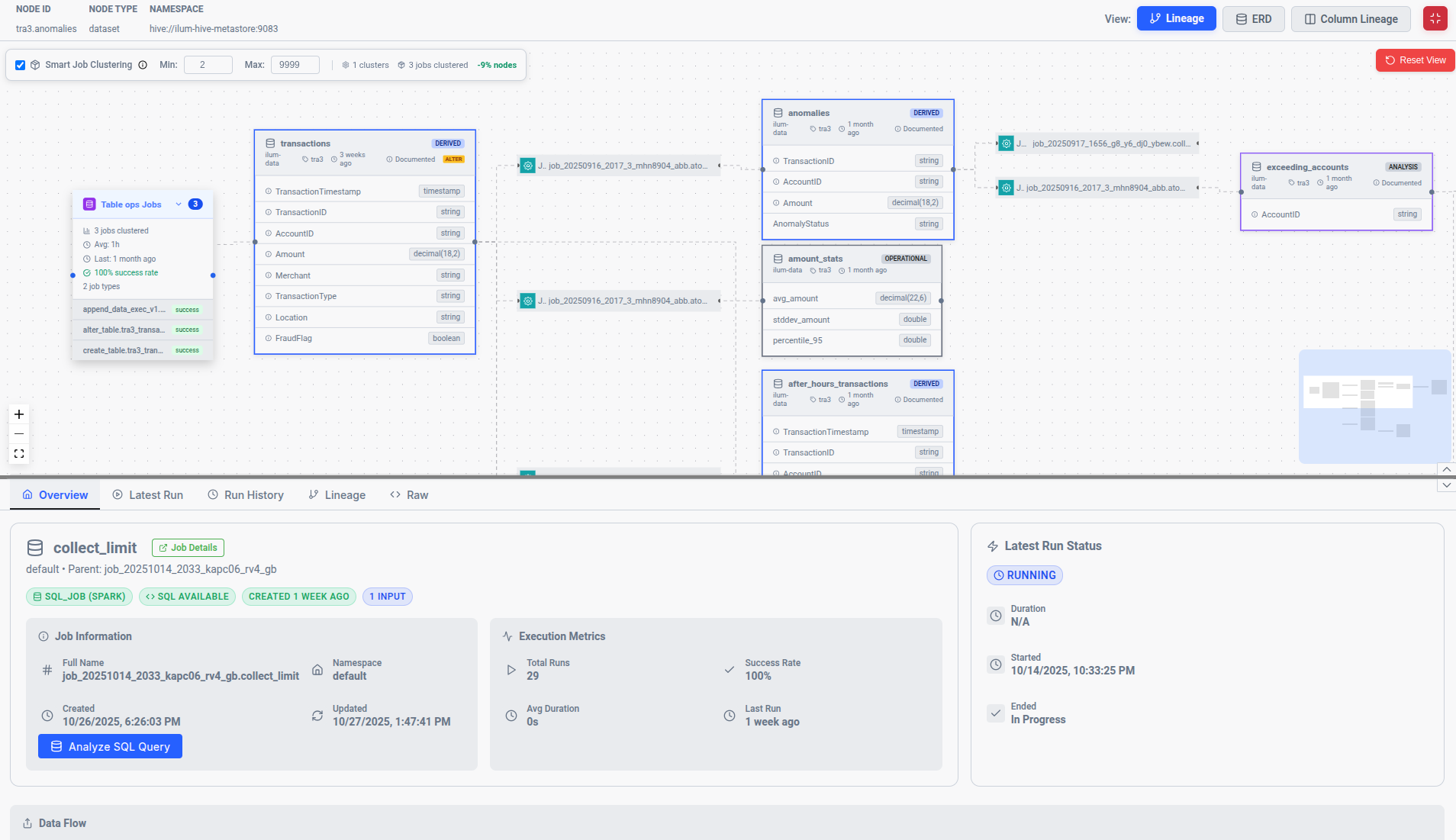
Smart Job Clustering
Ilum automatically groups similar jobs into compact clusters to maintain graph readability. This clustering:
- Prevents overwhelming visualizations in complex data pipelines
- Preserves drill-down capability to individual runs
- Maintains comprehensibility at scale for big data environments
Layer-Aware Data Flow
Track data evolution across refinement layers with:
- Key fields and data types displayed on table cards
- Clear upstream and downstream edges
- Visual layer badges (Bronze → Silver → Gold)
This layer awareness enables:
- Understanding data transformation stages
- Tracking data quality improvements across layers
- Identifying where data enters and exits each refinement stage
- Validating medallion architecture implementation
Operational Overlays
Job nodes display critical operational metrics:
- Last run timestamp: When the job last executed
- Average duration: Typical data processing times
- Success rate: Job reliability metrics
These overlays enable quick identification of bottlenecks and problematic jobs, helping data engineers improve data pipeline performance.
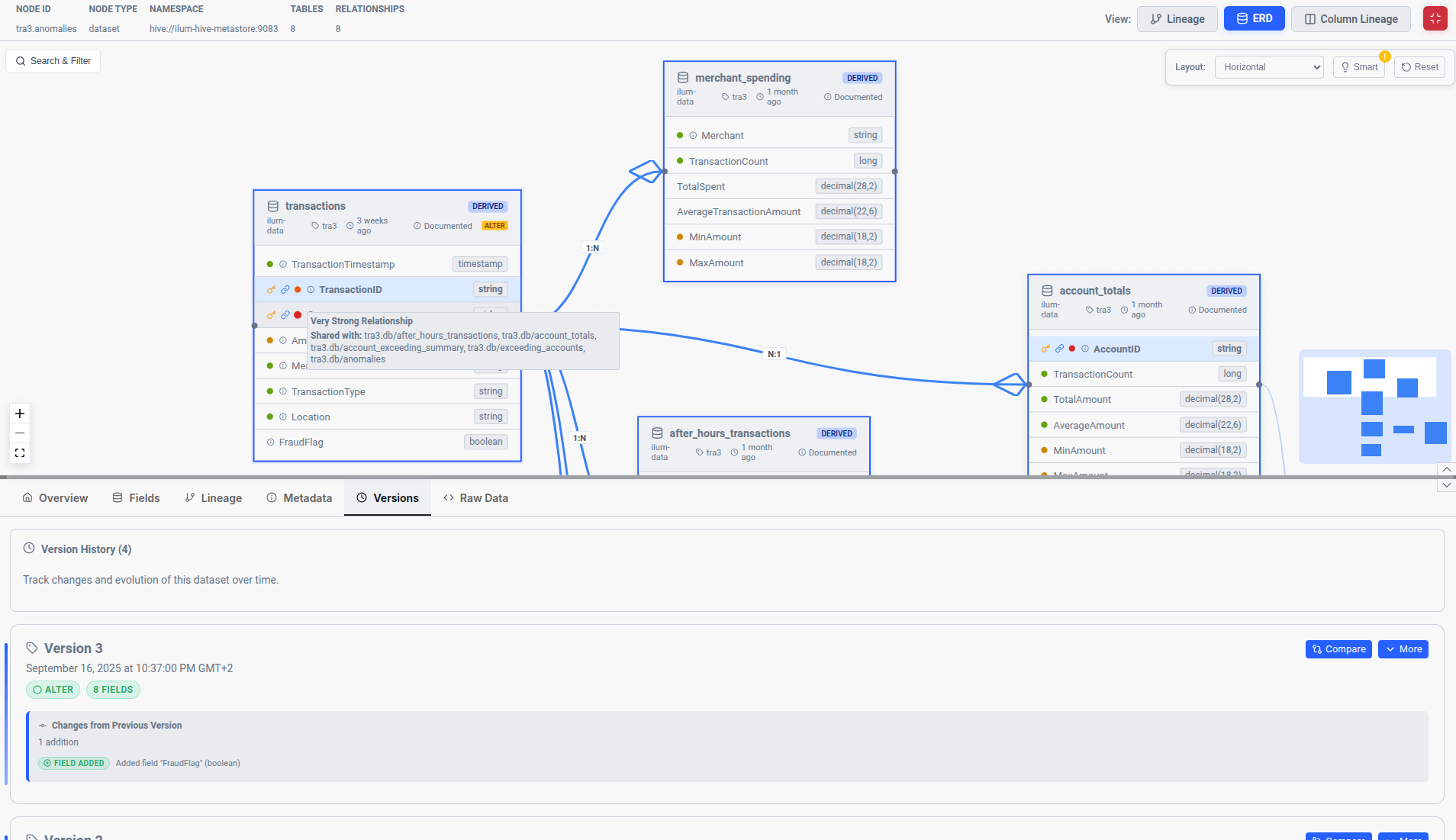
Version-Aware Datasets
The Versions tab for each data asset shows:
- Schema evolution over time
- Lifecycle events (e.g., OVERWRITE operations)
- Historical changes affecting downstream consumers
Understanding data across versions helps prevent surprises and enables proactive communication about breaking changes.
ERD ↔ Lineage Toggle
Switch between two complementary perspectives:
- Entity-relationship view: Table relationships and schema design
- Lineage view: Runtime data flow and job execution
Use ERD mode for schema design, then verify runtime behavior in Lineage mode to ensure data integrity.
Navigation Features
Navigate large graphs with:
- Mini-map: Bird's-eye view of complex lineage
- Zoom and pan: Smooth exploration of relationships
- Multi-select: Highlight multiple nodes simultaneously
- Status badges: Operational status indicators (OPERATIONAL, FAILED)
Data Lineage Search and Data Catalog Integration
Ilum's global search enables instant location of data assets, columns, and jobs within the data catalog.
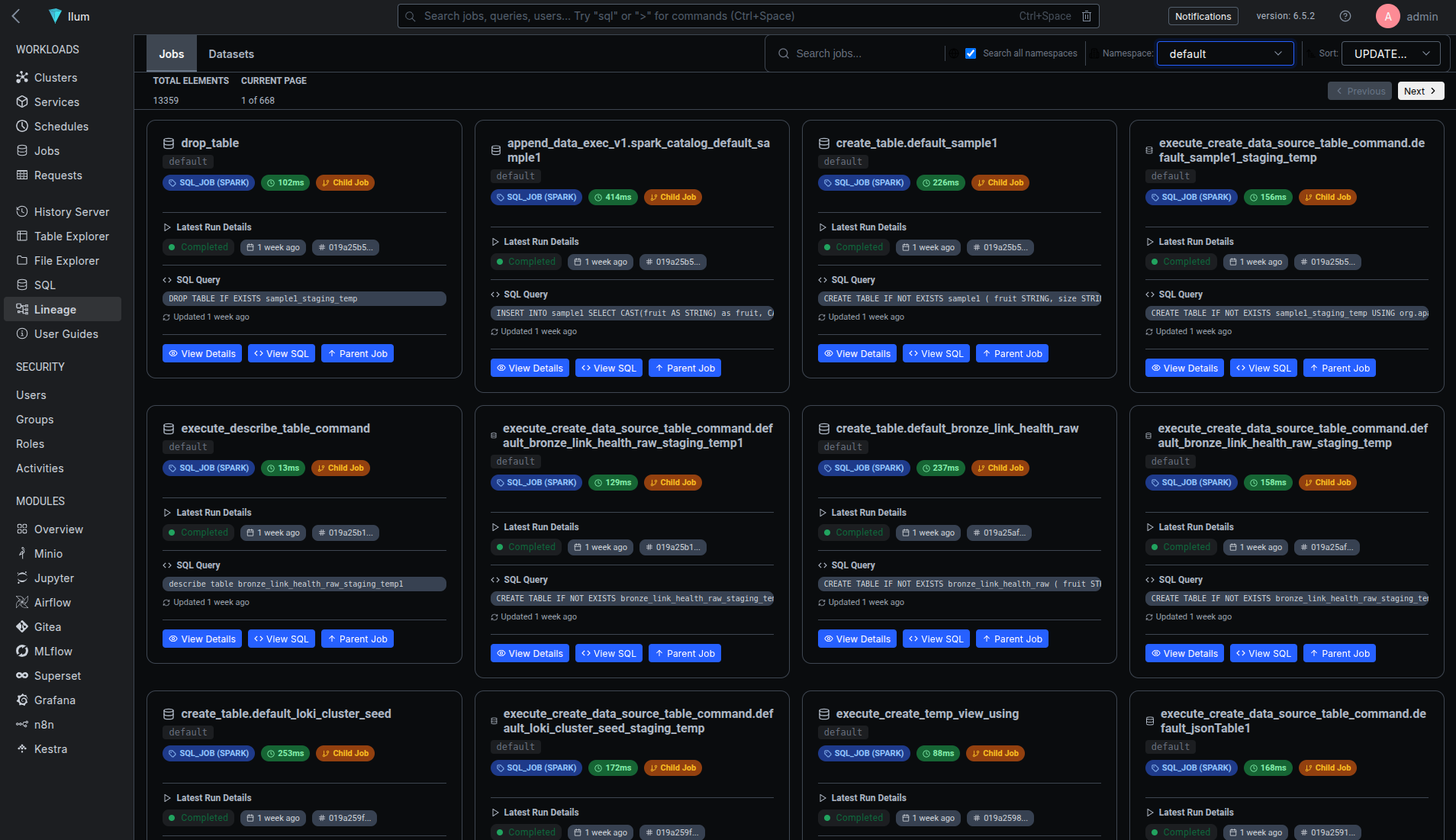
Search Capabilities
The unified search bar supports:
- Table/dataset names: Direct navigation to any table in your data catalog
- Column names: Find all occurrences of data elements across datasets
- Job names or IDs: Locate specific jobs by name or identifier
- Storage paths: Search by physical location (e.g.,
s3://bucket/path,gs://bucket/path)
Matching nodes are highlighted on the lineage graph for focused exploration, making it easy to track data across your organization.
Namespace-Aware Search
Control search scope:
- All namespaces: Query across the entire data platform
- Current namespace only: Limit to active namespace
Quick Actions
From search results:
- View Details: Open data asset or job details
- Open SQL: View the query that created or transformed the data
- Jump to Job: Navigate to job execution details
Data Catalog Indexing
Search results remain current through automatic reindexing of:
- Hive Metastore metadata
- Column-level metadata
- Lineage edges and relationships
Indexing occurs after each successful job run or schema change, ensuring the data catalog reflects the latest state.
Access Points
Access lineage search from:
- Any dataset's Lineage tab (search bar)
- The unified Jobs view
- The Datasets browser in the data catalog
Business Glossary & Data Classification
A business glossary provides a shared vocabulary for data assets across an organization. Ilum supports lightweight business glossary capabilities through its integrated metadata management and classification features.
Metadata Tagging with Marquez
Ilum's Marquez-based lineage service supports attaching custom metadata tags to datasets and jobs. These tags serve as business glossary entries, providing human-readable descriptions and classifications for data assets:
- Dataset Tags: Label tables with business context (e.g.,
customer-360,revenue-reporting,compliance-required) - Job Tags: Classify pipelines by business function (e.g.,
etl-finance,ml-training,regulatory-reporting) - Namespace Organization: Use Marquez namespaces to group assets by business domain or department
Tags are searchable via the lineage search interface, enabling users to discover data assets by their business meaning rather than technical names.
ABAC Classification Tags
Ilum's Data Access Control system provides classification tags that serve dual purposes (access governance and business glossary):
| Tag | Purpose | Governance Effect |
|---|---|---|
PII | Personally Identifiable Information | Triggers column masking for non-authorized roles |
Confidential | Business-sensitive data | Restricts access to authorized groups |
EU-Only | GDPR-regulated data | Enforces regional access policies |
Public | Non-sensitive, shareable data | No access restrictions |
These tags are applied at the column or table level in the catalog and are inherited by downstream datasets through lineage tracking.
Combine Marquez metadata tags (for business context) with ABAC classification tags (for access governance) to create a comprehensive, enforceable business glossary that bridges the gap between data discovery and data security.
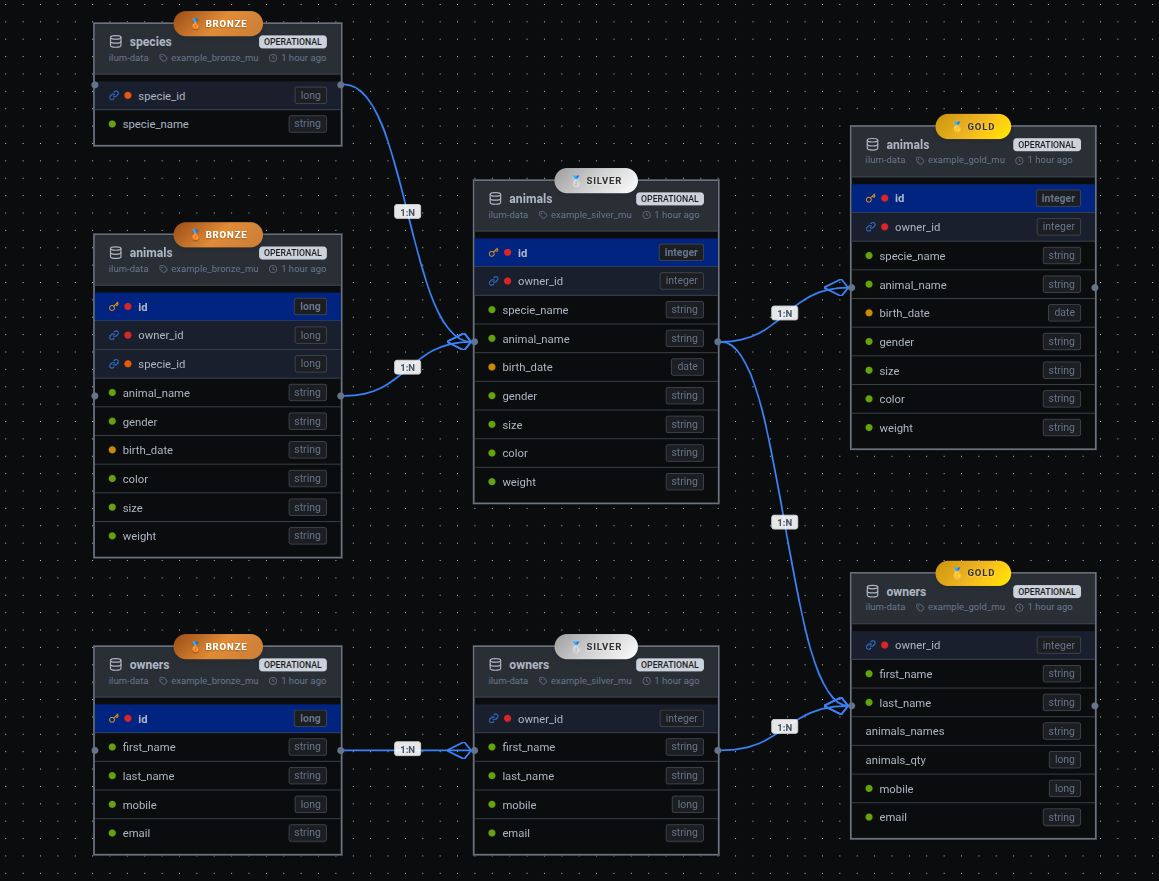
ERD View for Data Model Visualization
ERD (Entity-Relationship Diagram) View provides interactive data modeling with live operational context, enhancing the data catalog experience.
Layer-Aware Data Modeling
Tables display layer badges (Bronze → Silver → Gold), showing:
- Data quality levels at each stage
- Data transformation pipeline stages
- Medallion architecture documentation
Keys, Relations, and Cardinality
ERD View visualizes database relationships:
- Primary keys: Clearly marked on each table
- Foreign keys: Visual indicators for linked fields
- Cardinality indicators: Relationship types (1:N, 1:1, N:M)
Field-Level Schema
Each table card displays:
- Column names: All data elements in the table
- Data types: Type information for each column (e.g.,
id: long → integer) - Type evolution: Type changes across layers
Operational Context
Table nodes include real-time information:
- Freshness indicators: Recent data updates (e.g., "1 hour ago")
- Operational status: Current state (OPERATIONAL, STALE, FAILED)
- Data quality signals: Table health indicators
Join Visualization
Relationship connectors snap to exact key fields, showing:
- Columns participating in relationships
- Foreign key reference directions
- Table connection patterns in the data model
Navigation
Large data models remain manageable with:
- Smooth pan and zoom: Effortless navigation
- Tidy connectors: Automatically routed relationship lines
- Collapsible sections: Focus on relevant model portions
Use Cases for Data Lineage
Use Case: Data Quality Improvement
Trace data flow to identify where data quality issues arise. Data lineage enables root cause analysis by pinpointing the exact data transformation or data processing step that introduced errors. This use case helps ensure data quality across the entire data lifecycle.
Data lineage can help organizations:
- Identify data quality issues quickly
- Trace errors back to their source
- Validate data transformation logic
- Improve data reliability
Use Case: Regulatory Compliance
Regulations like GDPR and CCPA require transparent tracking of sensitive data. Data lineage provides clear audit trails documenting:
- Data movement across data systems
- Access and modification history
- Sensitive data handling and data provenance
Lineage can help demonstrate compliance and reduce regulatory risk.
Use Case: Impact Analysis
Before making data changes:
- Identify all downstream dependencies
- Assess schema modification impacts
- Plan data migration projects
- Minimize disruption to data consumers
Understanding data dependencies through lineage prevents unexpected failures.
Use Case: Data Cataloging and Discovery
Data lineage enhances the data catalog by providing:
- Data origin and data transformation details
- Dependency information between data assets
- Quality and suitability assessment capabilities
Lineage information integrated into the data catalog improves understanding for all users, enabling data discovery and data analytics initiatives.
Choosing the Right Data Lineage Tool
When selecting a data lineage tool, consider:
- Integration capabilities: Works with your existing data systems, data warehouses, and data pipelines
- Automated data lineage: Captures lineage without manual intervention
- Data lineage diagrams: Visualizes data flow effectively
- Data catalog integration: Enriches your data catalog with lineage information
- Scalability: Handles enterprise data volumes and complexity
- Data governance features: Supports compliance and data management requirements
A robust data lineage solution should provide end-to-end visibility and help manage data across complex environments. Ilum's lineage implementation, built on a battle-tested Marquez fork with upstream-first principles, provides production-ready data lineage capabilities with advanced features for enterprise data platforms. The lineage solution includes automated data lineage capture, comprehensive search capabilities, and operational overlays that help data engineers track data effectively across complex data pipelines.
How to Implement Data Lineage
Steps to Implement Data Lineage
Implementing data lineage involves several key steps:
- Define scope: Identify critical data assets and data sources to track
- Capture lineage: Profile data sources, document data mapping rules, and define data transformation logic
- Configure tools: Set up your data lineage tool to capture lineage from data systems
- Visualize data: Create data lineage diagrams to represent the flow of data
- Share and maintain: Distribute lineage information to stakeholders and update regularly
Data lineage enables organizations to track data systematically when following these steps.
Leverage OpenLineage Features
The OpenLineage listener is pre-configured with essential settings but supports advanced features:
- Custom job namespaces
- Manual dataset tagging
- Custom metadata capture
For details, see the OpenLineage documentation.
Keep OpenLineage Updated
The OpenLineage listener receives frequent updates with new features and metadata collection capabilities. Ensure you use recent versions to benefit from improvements like column-level lineage tracking.
Custom Spark Listeners
For additional or custom metadata capture, data engineers can implement custom Spark Listeners:
spark.extraListeners=com.example.CustomListener
Example custom listener in Scala:
import org.apache.spark.scheduler.{SparkListener, SparkListenerJobStart, SparkListenerJobEnd}
class CustomListener extends SparkListener {
override def onJobStart(jobStart: SparkListenerJobStart): Unit = {
// Custom logic to capture metadata when a job starts
println(s"Job started: ${jobStart.jobId}")
// Send metadata to your lineage service here
}
override def onJobEnd(jobEnd: SparkListenerJobEnd): Unit = {
// Custom logic to capture metadata when a job ends
println(s"Job ended: ${jobEnd.jobId}, result: ${jobEnd.jobResult}")
// Send additional metadata here
}
}
Ensure the custom listener is available on the Spark classpath. The spark.extraListeners property accepts comma-separated lists for multiple listeners.
Types of Data Lineage
Understanding the different types of data lineage helps organizations choose the right approach for their needs.
Forward Data Lineage
Forward data lineage traces data flow from data sources to all downstream consumers. It answers: "Where does this data go?"
Use forward data lineage to:
- Identify downstream dependencies before making data changes
- Assess impact of schema modifications
- Plan data migration projects
- Ensure consistency across dependent data systems
Backward Data Lineage
Backward data lineage traces data from its current location back to original data sources. It answers: "Where did this data come from?"
Use backward data lineage to:
- Perform root cause analysis on data quality issues
- Validate data transformation logic
- Debug data pipeline errors
- Audit data provenance for compliance
End-to-End Lineage
End-to-end lineage combines forward and backward perspectives, providing complete end-to-end data visibility from origin to destination. This comprehensive view enables:
- Complete data flow understanding
- Impact analysis in both directions
- Schema evolution tracking
- Full audit trail maintenance
Data lineage can help organizations track data across the entire data lifecycle when using end-to-end lineage.
Benefits of Data Lineage
Get More Value from Data
One of the key benefits of data lineage is the ability to get more value from data assets. When data lineage helps organizations understand data origins and data transformation, they can ensure data quality and accuracy. This increased confidence enables businesses to use data lineage for analysis and decision-making.
By having end-to-end lineage, data engineers can quickly identify and rectify issues in the data pipeline, ensuring that insights derived are reliable and actionable.
Enhancing Data Governance
Data governance is significantly enhanced through data lineage implementation. Data lineage provides a clear and auditable flow of data, which is critical for regulatory compliance and internal control. Organizations can track data movement and data changes from data sources to final destinations.
The lineage information enables better data management, accountability, and transparency: essential components of robust data governance frameworks.
Critical Data Management
Data lineage is critical for data management in complex enterprise data landscapes. It allows organizations to effectively manage data by providing visibility into how data moves across different data pipelines and data warehouses.
Implement data lineage to quickly identify the impact of data changes and trace data quality issues back to their root cause. This is invaluable for maintaining data quality and preventing data-related incidents.
Common Challenges in Data Lineage Implementation
Complex Enterprise Data Landscapes
Modern enterprise data environments have numerous data sources and intricate data pipelines. Ensuring comprehensive coverage and accurate data mapping across all data systems requires:
- Systematic approach to metadata capture
- Regular validation of lineage information
- Collaboration between data engineers and stakeholders
Without data lineage, managing complex data systems becomes significantly more difficult.
Maintaining Data Lineage Quality
As data systems evolve and data transformation processes change, lineage information must remain accurate. Address this through:
- Regular audits of lineage data
- Automated validation processes
- Consistent documentation practices
Data lineage helps organizations maintain accurate metadata about their data assets over time.
Troubleshooting
No Lineage Data Captured
If no lineage data appears:
- Verify the lineage service (Marquez) is running and accessible
- Ensure OpenLineage listener dependencies are included in Spark jobs
- Check Spark job logs for OpenLineage listener errors
- Confirm URL and endpoint configuration for the lineage service
- Verify custom configurations are reflected in job properties
Ilum will set everything up for you.
Learn More About Data Lineage
Understanding Data Lineage Concepts
Data lineage tracks the detailed journey of data through your organization. Understanding how data lineage works, the types of data lineage available, and the benefits of implementing data lineage helps organizations use data more effectively.
Key concepts include:
- Data provenance: The origin and history of data
- Data flow: Movement of data through pipelines
- Data transformation: Operations that modify data
- Data mapping: Relationships between source and target data elements
Best Practices
- Start small: Begin with critical data assets and expand coverage
- Automate: Use automated data lineage tools to reduce manual effort
- Integrate: Connect lineage with your data catalog for comprehensive data management
- Validate: Regularly verify lineage accuracy and completeness
- Educate: Train data engineers and users on how to use data lineage effectively
Data lineage is essential for modern data governance and helps organizations ensure data quality, maintain compliance, and get more value from their data assets.